Sri Lanka’s AI conversation is shifting from curiosity to capability. The question is no longer whether large language models can answer questions, but whether they can answer them the Sri Lankan way in Sinhala or Tamil, grounded in local law, aligned to school syllabi, and aware of how our institutions, markets, and public services actually work. This is the idea behind a “Sri Lanka LLM”: not a bigger brain, but a brain educated on Sri Lanka.
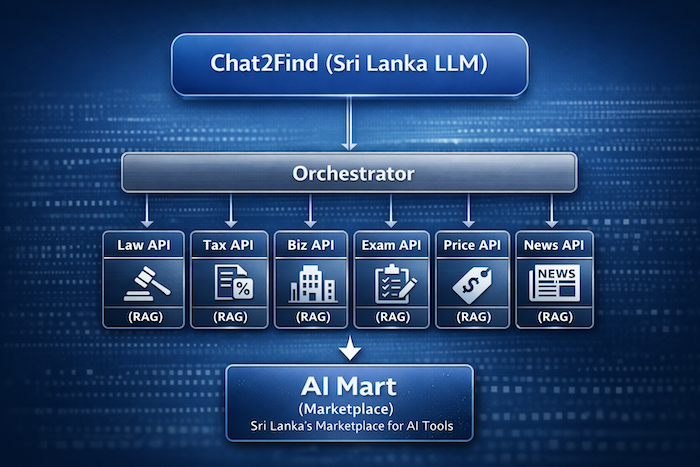
At the heart of this transition is Chat2Find which has been steadily building the most critical component for a Sri Lanka-focused model: curated, domain-specific knowledge bases drawn from authoritative local sources. Instead of attempting to train a model from the ground up, the approach connects powerful LLM (Large Language Model) to these live data systems through retrieval, orchestration, and multilingual alignment. In effect, Chat2Find is integrating an LLM into its existing data empire across multiple pillars – a design that is more dynamic and responsive than conventional models trained once on static data.
The data pillars behind a Sri Lanka LLM
Within the Chat2Find ecosystem, several vertical knowledge systems function as living, continuously updated corpora that power a Sri Lanka-focused LLM. LankaLaw provides Acts, gazettes, case law, amendments, and legal interpretation. LankaTax captures the tax code, circulars, practical examples, and compliance guidance. LankaBiz contributes company data, regulatory filings, and market intelligence. ExamPazz supplies O/L and A/L past papers, model answers, and teacher explanations aligned with local syllabi. Cheap2Find adds product and price intelligence from across the market, while NewsDive introduces a real-time news aggregation layer that tracks developments across publishers. Together, these systems form the dynamic knowledge backbone behind Chat2Find’s Sri Lanka AI layer.
Individually, these platforms function as specialized AI search and explanation engines. Collectively, they form the backbone of what a Sri Lanka LLM needs most: fresh, structured, trilingual knowledge.
From many AIs to one orchestrated intelligence
The breakthrough is not merging all this data into a single model. Instead, Chat2Find is building an orchestration layer where a master LLM decides which expert system to consult for each question. A query about VAT routes to the tax engine. A question about the 13th Amendment routes to the law engine. An economics past-paper explanation routes to the exam engine. The LLM’s role is to retrieve, reason, and rewrite in the user’s preferred language and level.
This architecture keeps knowledge current (as each system updates daily) while allowing the LLM to provide natural, conversational answers that feel locally fluent.
“Chat2Find LLM is right around the corner. When it launches, it will be open weights and open source – free for everyone, forever,” says Avishka Sumanadeera, the 28-year-old founder of Chat2Find. “Sri Lanka’s knowledge infrastructure – our laws, our syllabus, our tax code should not be locked behind a paywall. We built this for every student, every small business owner, every citizen. Soon, it will be in your hands. And we’re not stopping there.
AI Mart: a marketplace for Sri Lankan AI expertise
Beyond its internal knowledge systems, Chat2Find has already created the country’s first marketplace for AI tools AI Mart. This platform allows Sri Lankan developers, researchers, teachers, lawyers, accountants, and domain experts to onboard their own trained AI systems built on Sri Lankan data. These expert AIs become discoverable services within the ecosystem, expanding the national knowledge network beyond a single organization.
As AI Mart grows, the Sri Lanka LLM will not rely only on Chat2Find’s own databases, but will also be able to access these external expert knowledge bases. This turns the model into a national AI infrastructure where local expertise can plug in, contribute, and be instantly usable by citizens through a unified interface.
We’ve also launched AI Mart at aimart.lk, Sri Lanka’s first AI marketplace – a single window for locally built AI tools trained on Sri Lankan data for Sri Lankan use cases, without the need to depend on foreign platforms or navigate international pricing. It’s all here.” said Avishka Sumanadeera
Why multilingual alignment matters
A genuine Sri Lanka LLM must move effortlessly between Sinhala, Tamil, and Sri Lankan English. Exam content, legal text, and public information often exist in parallel across languages. By aligning these sources, the system can retrieve in one language and respond in another, preserving meaning and local terminology. This is a practical path to trilingual AI without the enormous cost of training a foundation model from scratch.
Current progress
Today, the core components within the Chat2Find ecosystem are already operational. Domain-specific RAG systems are actively running across law, tax, business, education, and price intelligence, each powered by curated Sri Lankan data sources. Clean Sinhala and Tamil text pipelines have been established using real documents, gazettes, and exam material to ensure high-quality multilingual inputs. APIs are in place that allow an orchestration LLM to query each knowledge base in real time, enabling live retrieval instead of relying on static knowledge. Early tool-calling workflows are also functioning, allowing the model to identify and consult the relevant Sri Lankan “expert” system before generating its response
The result is an assistant capable of what generic AI systems cannot achieve: linking a classroom concept to a real Sri Lankan company example, explaining the related tax implication, citing the relevant legal provision, and even comparing the current market price of the required textbook – all within a single response. This level of cross-domain reasoning is beyond the reach of any single source or standalone model, and becomes possible only within an integrated ecosystem such as Chat2Find LLM

